Destination set up
Pipeline setup is a three step process:
- Ingestion configuration
- Dedupe and Scheduling
- Destination set up
Destination Setup
The last step is to setup the destination.
ELT Data writes data to the blob (Azure, AWS, GCP) and also to the defined database location.
Let's assume we are fetching the General Ledger everyday from Netsuite. Here's the corresponding config:
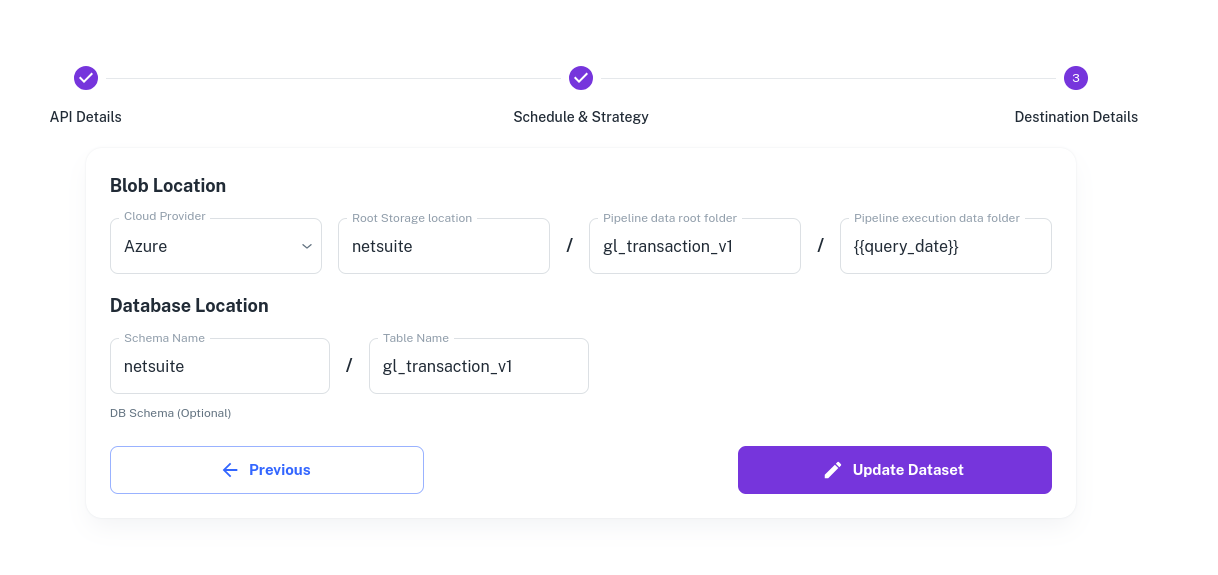
Blob setup
Cloud Provider - Select if Azure/AWS/GCP
Root Storage Location - The root folder or bucket where the data should be kept. In the above case, we have a separate location for Netsuite. This corresponds to the source level folder.
Pipeline data root folder - This is a dedicated space for General Ledger. We would be fetching other data from Netsuite too and this level corresponds to the data specific folder.
Pipeline Execution Data folder - This space corresponds to the execution specific data. We have named it {{query_date}}. {{query_date}} is a dynamic variable and a new folder gets created for each new {{query_date}}
Here's the blob output view corresponding to the above definition:
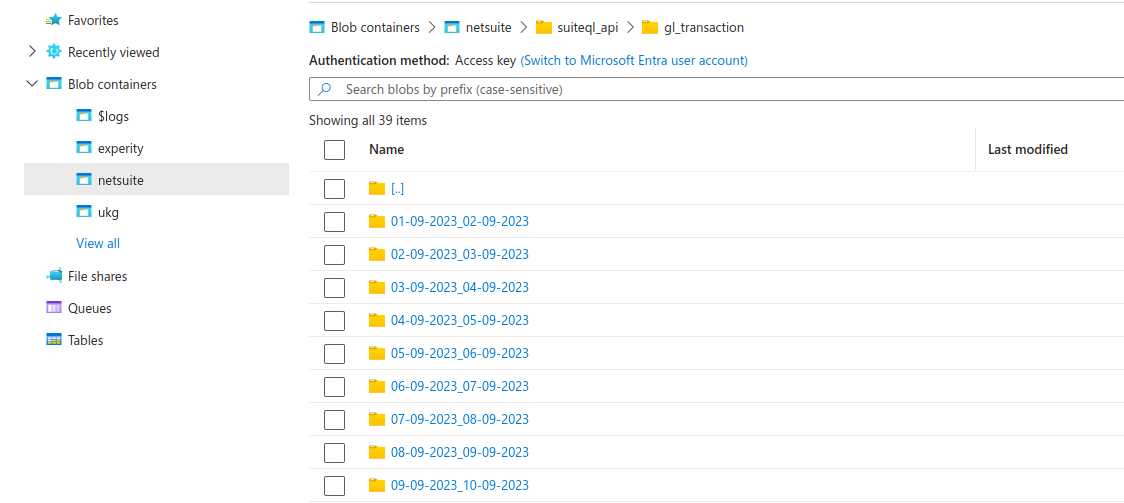
Following are the other folders which exist in the Blob:
deduped - contains the deduped data. DO NOT delete this folder as this folder is used for incremental loads.
final - contains the flattened dedupe data.
- final/csv - contains the flattened deduped data in CSV format.
- final/csv/single_file.csv - the merged, non partitioned CSV file in the CSV folder. This data is loaded into the DB. You can pick it p from the CSV folder and skip the DB tables if you want to.
schema - contains the schema evolution information of the dataset. You can navigate this folder and view the current schema and also how the schema has evolved so far.
{root}/metadata - this contains the temporary encrypted API credentials (oauth2 access tokens) for making API calls.
Database setup
ELT Data uses SQL Alchemy to write data to the destination. The following databases are supported - https://docs.sqlalchemy.org/en/20/dialects/index.html
If a given database doesn't exist, please write to contact@eltdata.io for setup.
ELT Data does truncate and load of the tables. The data used to load the tables is picked up from the Blob. The tables serve as a front-end for the data in the Blob. Please make sure the given schema exists.
For details on data flattening and schema management please see here.